TL;DR: We develop an online adaptation system that includes a
cross-embodiment locomotion policy and a lightweight online adaptation module.
The adaptation module accurately infers embodiment parameters from short interaction histories
(≈0.5 s). On a Unitree Go2, in both simulation and the real world, our policy with adaptation matches an
oracle policy under severe embodiment uncertainty and changes (e.g., locked leg, added payload), where a base
policy without adaptation fails.
Abstract
Humans effortlessly adapt their movements as their bodies change due to aging, injury, or the use of tools,
yet most learning-based robot controllers struggle when their hardware properties change. While recent work
trains cross-embodiment policies through large-scale embodiment randomization, these methods typically assume
the embodiment at deployment is known. In this work, we propose an online embodiment adaptation framework
for quadrupedal locomotion that explicitly infers embodiment parameters from interaction histories and
conditions control on the inferred embodiment. Our approach combines a generalist embodiment-aware policy
trained under extensive randomization with a lightweight adaptation module that identifies embodiment
properties from online interactions within half a second. In simulation, our approach accurately estimates
joint limit and payload mass changes, and outperforms an implicit end-to-end baseline. On the real-world
Unitree Go2 robot, our system enables stable locomotion under severe embodiment uncertainty, including a fully
locked leg or payload addition of 5 kg, where policies without adaptation fail. These results demonstrate
that explicit online embodiment adaptation can bridge the gap between cross-embodiment training and robust
real-world deployment under embodiment uncertainty.
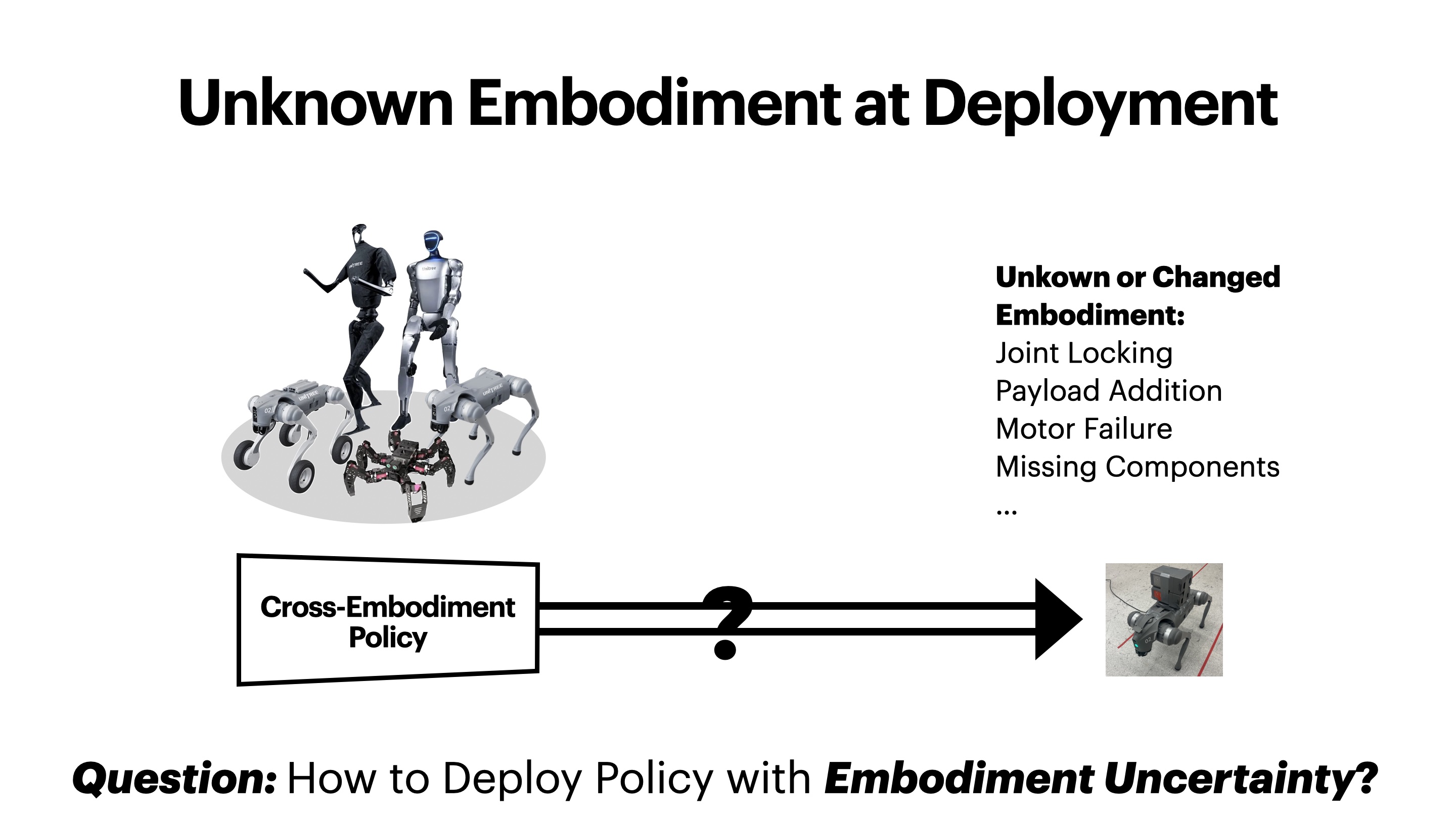
Problem
A cross-embodiment policy can be trained over many robot bodies, yet the
true embodiment at test time may be unknown or may change: joint locking, payload addition,
motor failure, missing components, and other hardware differences. The problem is how to control well when
embodiment itself is uncertain—the setting summarized in the figure below.
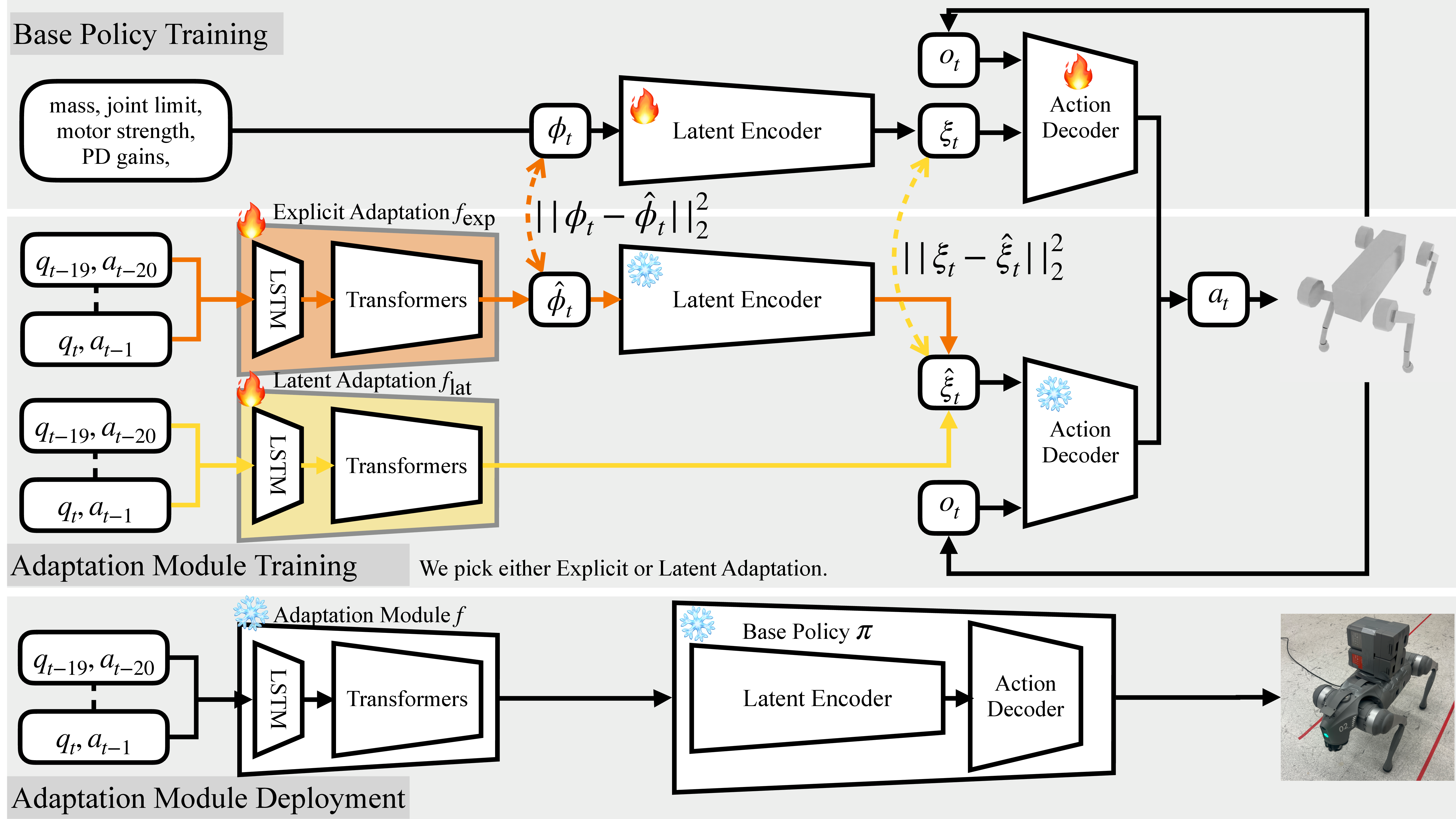
Method
A base policy is trained across randomized embodiments with access to ground-truth
embodiment descriptors. We then train an adaptation module to infer embodiment parameters
from a short interaction history so the base policy can condition on them. The module follows
two pathways: it predicts either explicit physical parameters (explicit adaptation) or latent
embodiment representations (latent adaptation).
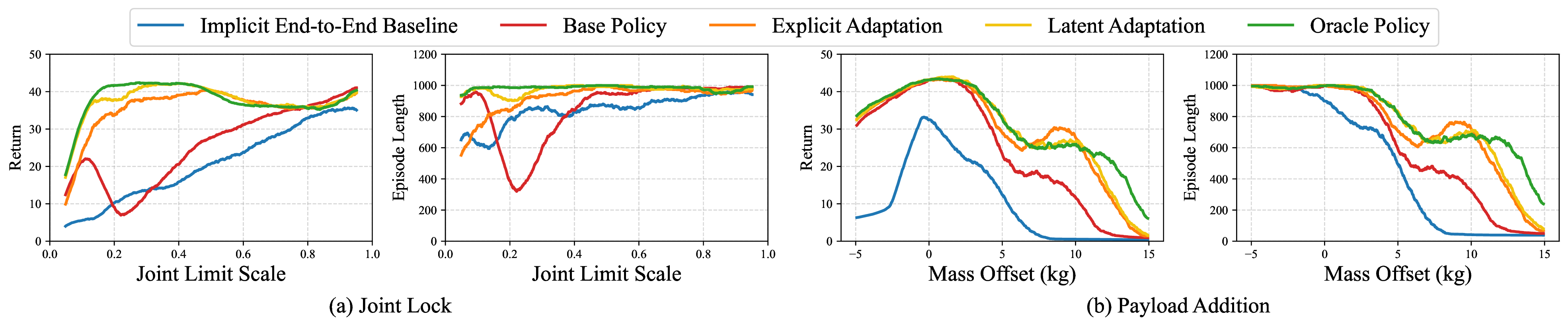
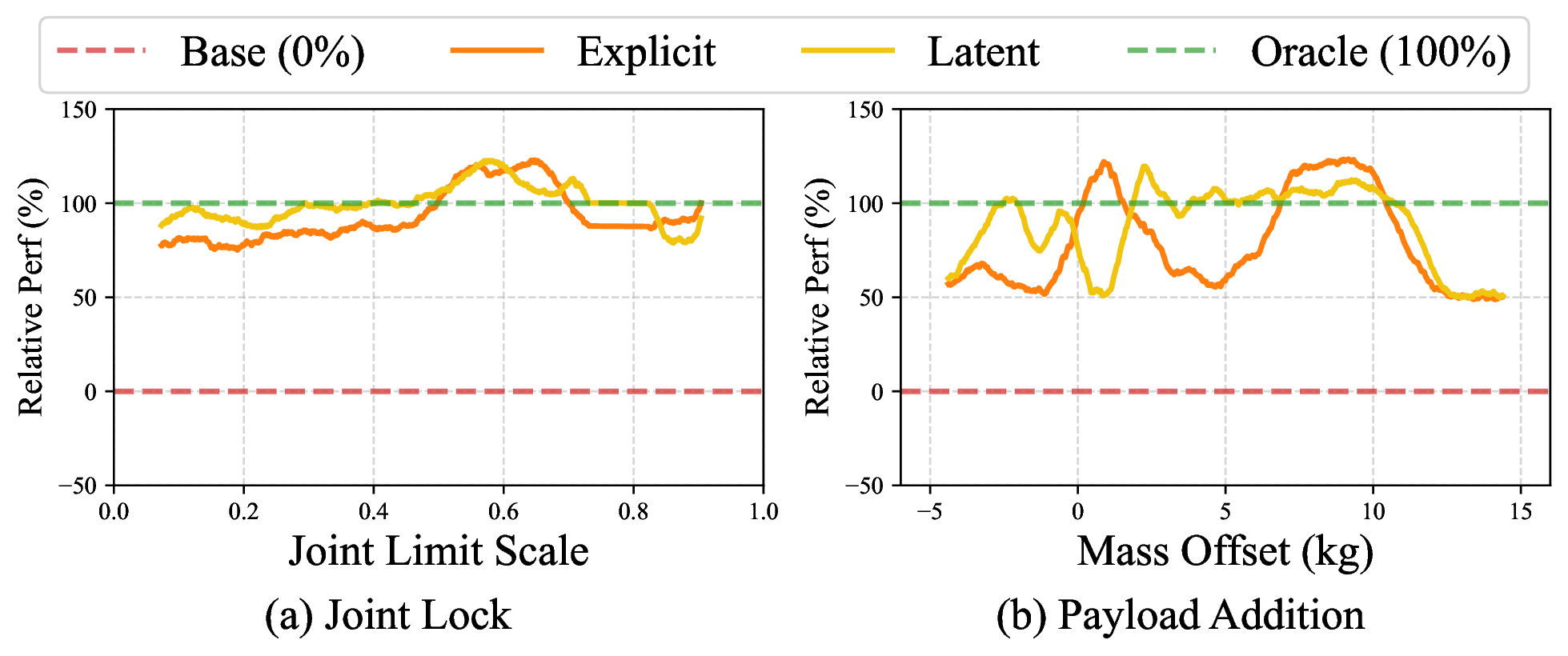
Simulation Performance
Below we plot mean episode return and episode length versus joint limit scaling and trunk mass offset for
different policies. The oracle and base policies mark the performance bounds. Policies with adaptation—both
explicit and latent adaptation—match the oracle policy (which receives ground-truth embodiment descriptions)
and largely outperform the base policy (which does not).
Real-World Performance
Experiment 1
On Unitree Go2, we compare policies with and without explicit adaptation under two conditions: (1)
front-right leg joint locking scaled to 0.3, and (2) a 5.0 kg trunk payload. These embodiment
uncertainties are introduced at the start of the episode. We form the following four experiments:
(a) With adaptation under joint limit modification. (b) Without adaptation
under joint limit modification. (c) With adaptation under payload mass addition.
(d) Without adaptation under payload mass addition. Our explicit adaptation policy enables
walking with one leg locked or carrying a heavy load; the base policy fails catastrophically in these settings.
Below: image streams and video.
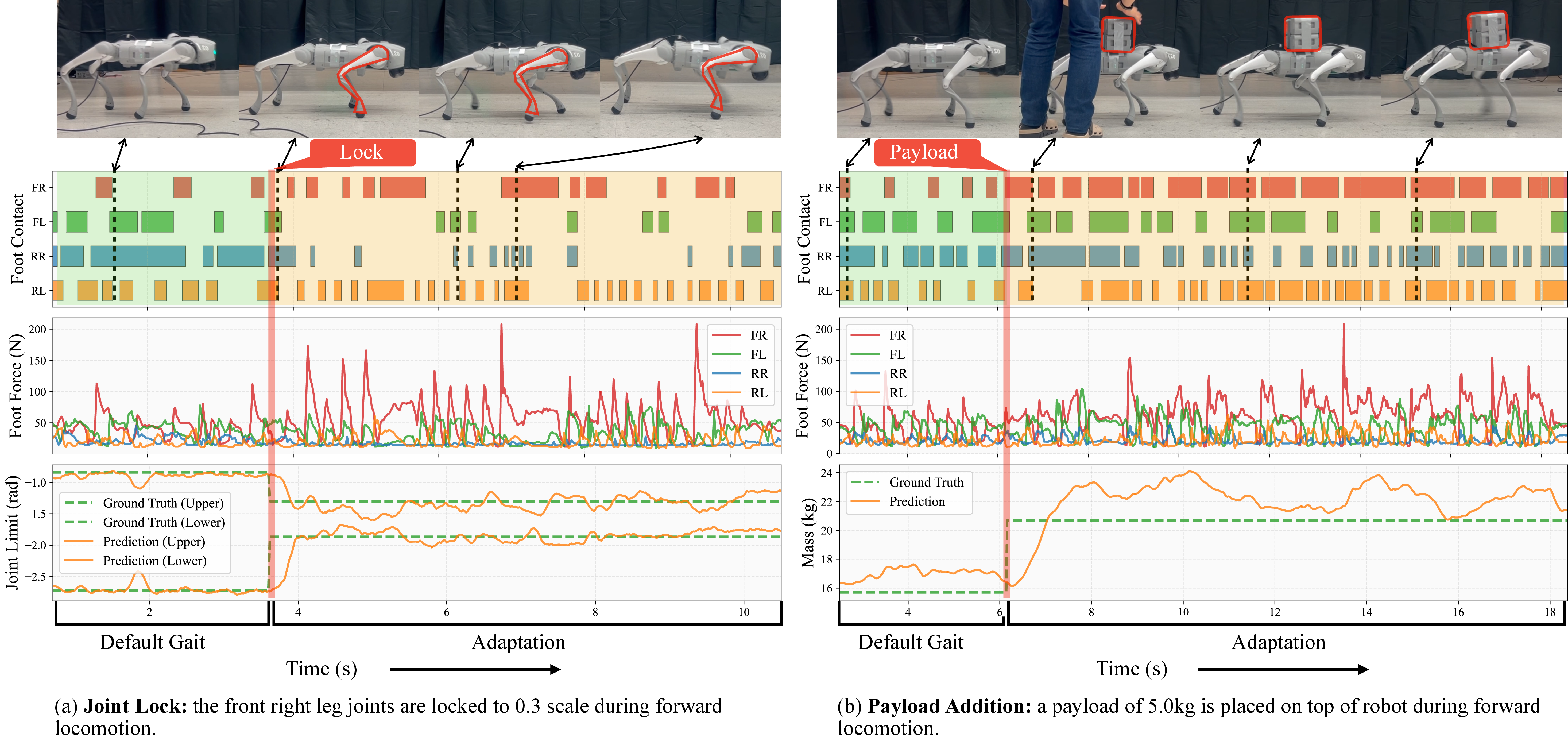
Experiment 2
When embodiment changes mid-episode (e.g., joint range suddenly reduced or payload added),
the adaptation module updates within roughly half a second; the policy then switches to a gait consistent with
the new body. Below: representative frame sequences from selected trials, followed by a
high-resolution qualitative video.
@misc{li2026online,
title={Online Embodiment Adaptation for Quadrupedal Locomotion},
author={Li, Dichen and Ai, Bo and Bohlinger, Nico and Peters, Jan and Christensen, Henrik I. and Su, Hao},
year={2026},
note={Preprint}
}